관계대수
관계 데이터 모델
관계 데이터 모델에서 지원하는 언어는 총 2가지가 있다.
- 관계 해석 - 원하는 데이터만 명시하고 질의를 "어떻게 수행할 것인가"는 명시하지 않는 선언적 언어
- 관계 대수 - "어떻게 질의를 수행할 것인가"를 명시하는 절차적 언어
관계 대수
릴레이션들을 다루는 연산들
기존의 릴레이션들로부터 새로운 릴레이션을 생성한다. => 입력값, 출력값이 모두 릴레이션이다.
연산자들을 적용하여 보다 복잡한 관계 대수식을 점차적으로 만들 수 있다. 기본적인 연산자들의 집합으로 이루어졌다.
결과 릴레이션은 또 다른 관계 연산자의 입력으로 사용될 수 있다.
특징
- 단일 혹은 두 개의 테이블들을 입력 받아 결과 테이블을 생성한다.
- 집합 연산을 토대로 만든 것이 관계 대수이며, 기본적으로는 집합 연산자에 속한다.
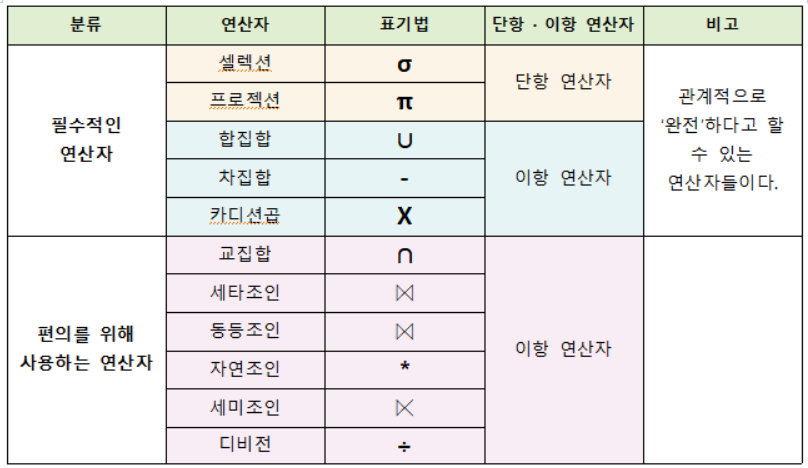
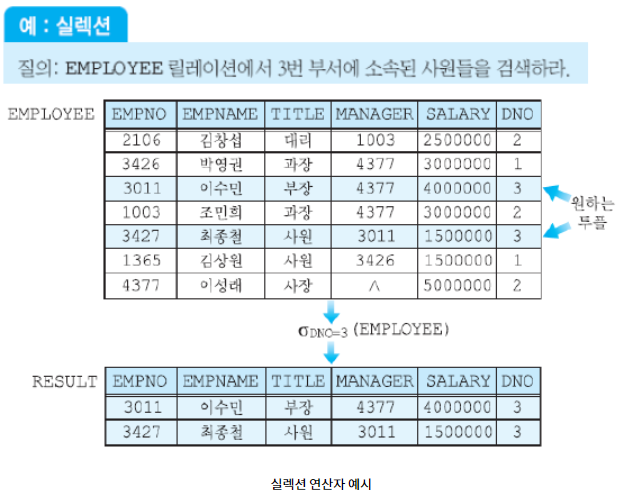
셀렉션(Selection)
- 릴레이션 R에서 어떤 선택조건을 만족하는 튜플들을 선택(원하는 데이터를 수평적으로 도출)
- 결과 릴레이션은 R과 동일한 애트리뷰트(속성)을 가짐
- 로 표현
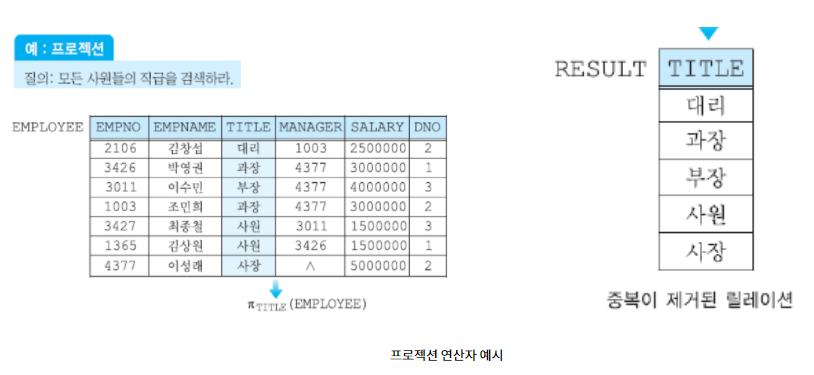
프로젝션(Projection)
- 한 릴레이션의 애트리뷰트들의 부분 집합을 구함(원하는 데이터를 수직적으로 도출)
- 중복 튜플 존재 X
- 로 표현
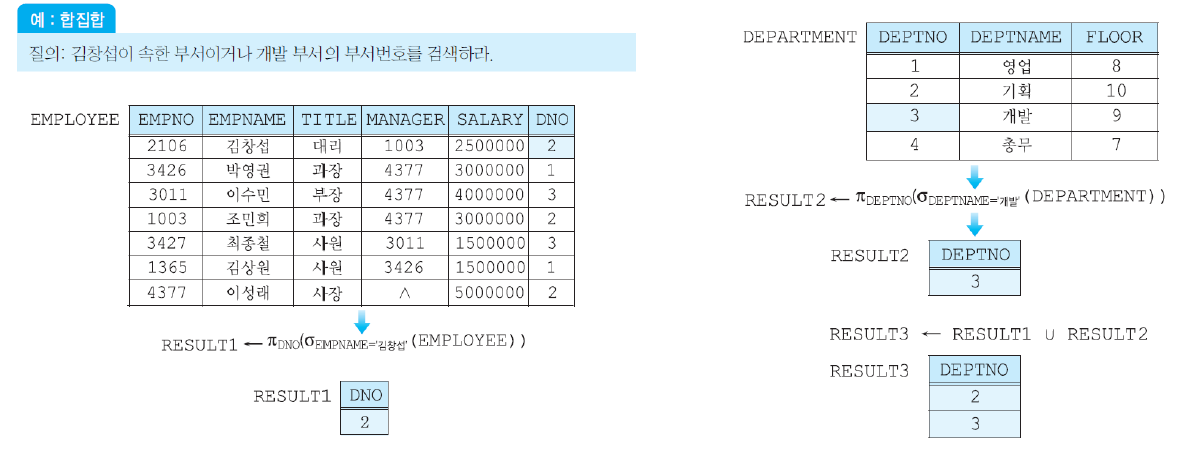
합집합(Union)
- 릴레이션1에 있거나, 릴레이션2에 있는 튜플들로 이루어진 릴레이션을 반환
- 결과 릴레이션에서 중복된 튜플들을 제거
- 로 표현
교집합(Intersection)
- 릴레이션1과 릴레이션2에 동시에 속하는 튜플들로 이루어진 릴레이션
- 로 표현

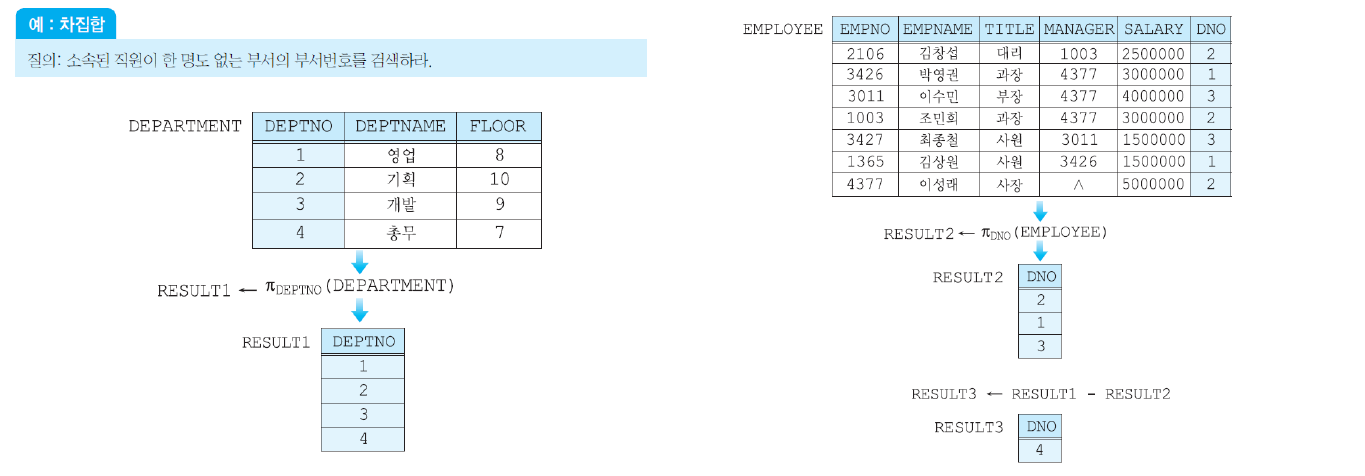
차집합(Relative Complement)
- 릴레이션R과 릴레이션S에 대해 R에는 속하지만 S에는 속하지 않은 투플들로 이루어진 릴레이션
- 로 표현
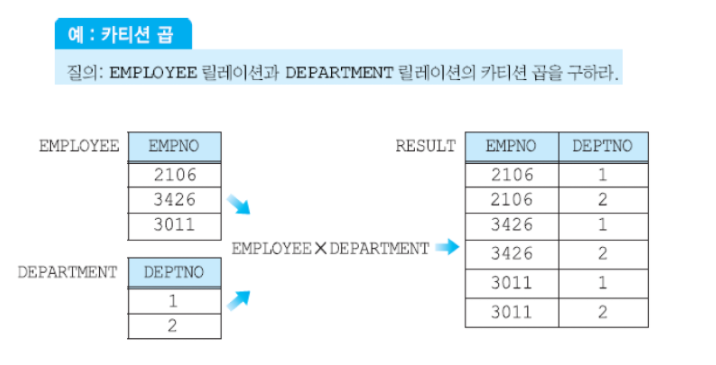
카티션 프로덕트(카티션 곱 연산자(Cartesian Product))
- 카디날리티가 i인 릴레이션 R(A1, A2, ... An)과 카디날리티가 j인 릴레이션 S(B1, B2, ... Bn)의 카티션 곱 R X S는 차수가 n+m이고 카디날리티가 i*j이고, 애트리뷰트가 (A1, A2, ... An, B1, B2, ... Bn)이다
- R과 S의 튜플들의 모든 가능한 조합인 릴레이션, 카티션 곱의 결과 릴레이션은 크기가 매우 클 수 있다.
- 유용하지 않음(보통 카티션 곱의 일부분만 원하기 때문)
- 로 표현
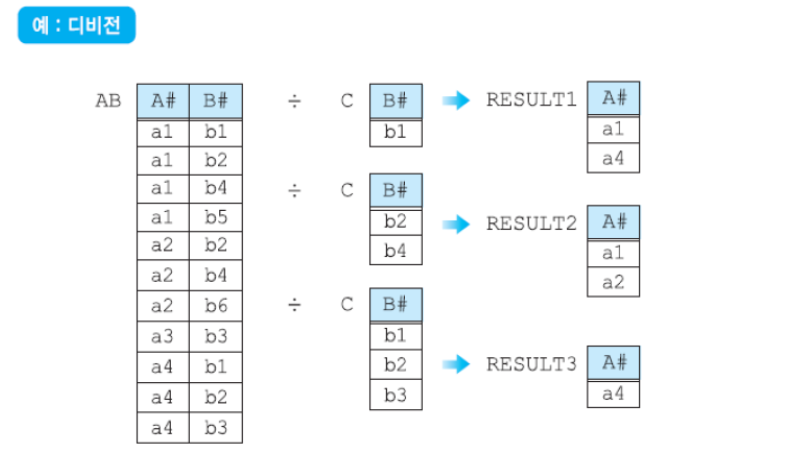
디비전(Division)
- 차수가 n+m인 릴레이션R과 차수가 m인 릴레이션S의 디비전 R / s는 차수가 n이고, S에 속하는 모든 튜플 u에 대하여 tu가 R에 존재하는 투플 t들의 집합
- 로 표현
조인(Join)
두 개의 릴레이션으로부터 연관된 튜플들을 결합하는 연산자이다. 관계 데이터베이스에서 두 개 이상의 릴레이션들의 관계를 다루는데 매우 중요한 연산자
예시 : 세타 조인, 동등 조인, 자연 조인, 외부 조인
나올 수 있는 면접 질문
- 관계대수란?
- 관계대수의 종류와 각각의 사용방법은?
- 셀렉션과 프로젝션의 차이는?
참고 url
기여자

HelloNaks
📦