크루스칼
크루스칼 알고리즘이란?
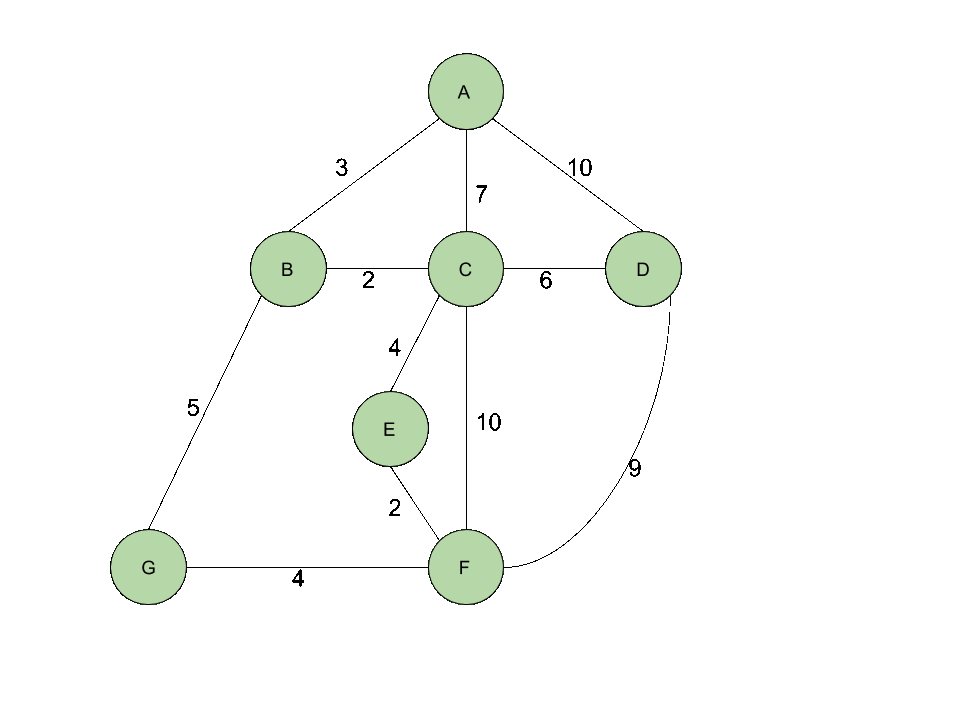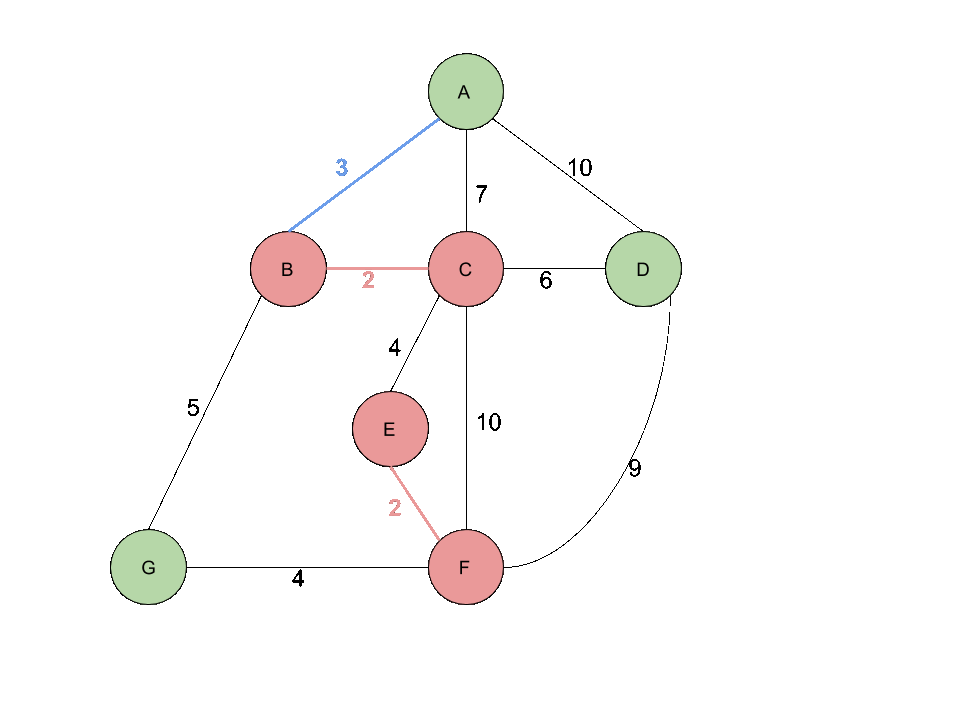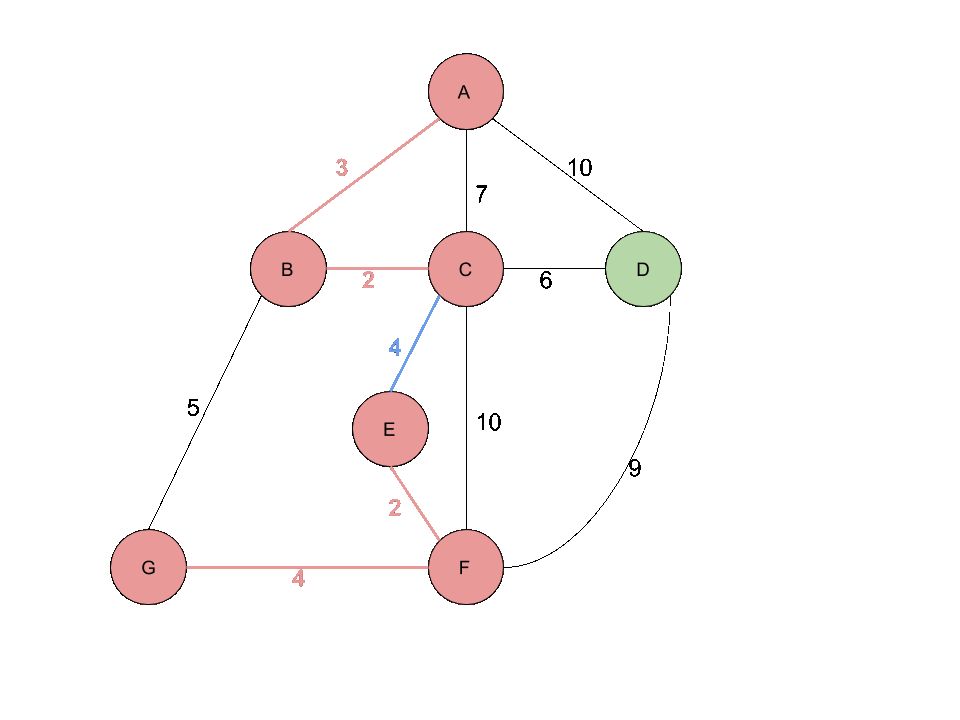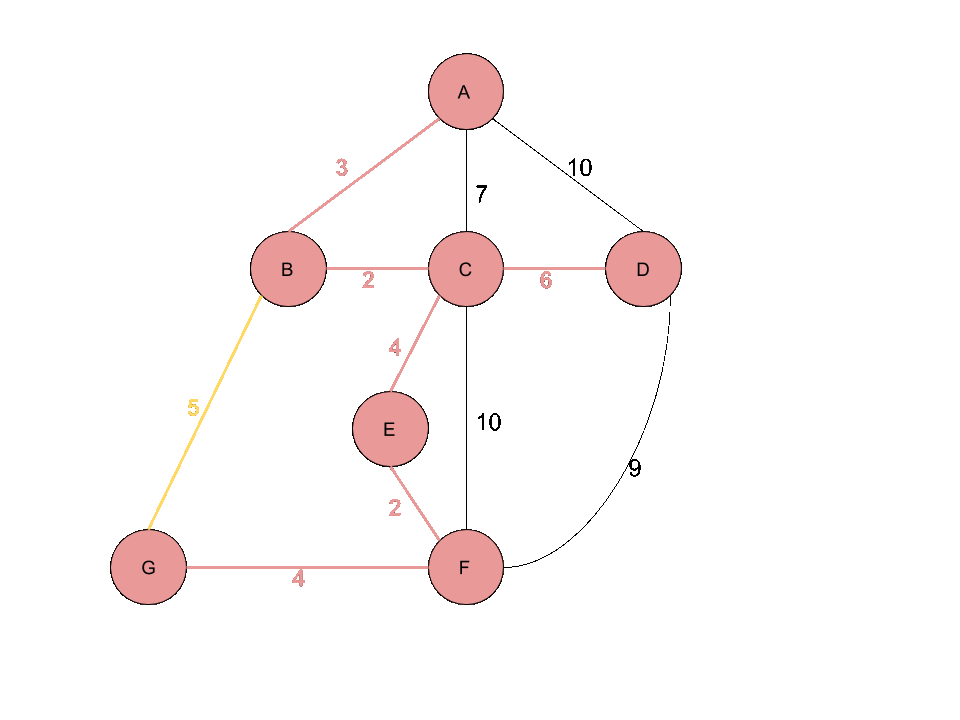
이미지 출처 : https://onepwnman.github.io/MST/
크루스칼 알고리즘 (kruskal)은 가장 적은 비용으로 모든 노드를 연결하기 위해 사용하는 알고리즘이다. 다시 말해 최소 비용 신장 트리(MST)를 만들기 위한 대표적인 알고리즘이다.
스패닝 트리 (Spanning Tree)
스패닝 트리는 그래프 내의 모든 정점을 포함하는 트리이며 다음과 같은 특징을 가진다.
- 스패닝 트리는 그래프의 최소 연결 부분 그래프이다
- n개의 정점이 있을 때 스패닝 트리의 간선 수는 (n-1)개이다
- 스패닝 트리는 트리의 특수한 형태이므로 모든 정점들이 연결 되어 있어야 하고 사이클을 포함해서는 안된다
최소 스패닝 트리 (MST)
최소 스패닝 트리는 스패닝 트리 중에서 사용된 간선들의 가중치 합이 최소인 트리이다. 최소 스패닝 트리는 다음과 같은 특징을 가진다.
- 간선의 가중치 합이 최소여야 한다
- n개의 정점을 가지는 그래프에 대해 반드시 (n-1)개의 간선만을 사용해야 한다
- 사이클이 포함되어서는 안된다
크루스칼 알고리즘 과정
1. 그래프의 간선 가중치를 오름차순으로 정렬한다
2. 정렬된 간선 리스트에서 순서대로 사이클을 형성하지 않는 간선을 선택한다
- 가장 낮은 가중치를 지닌 간선을 선택한다
- 사이클을 형성하는 간선을 제외한다
3. 해당 간선을 현재의 MST 집합에 추가한다
위와 같은 크루스칼 알고리즘 과정을 예시로 나타내면 다음 과정과 같다.
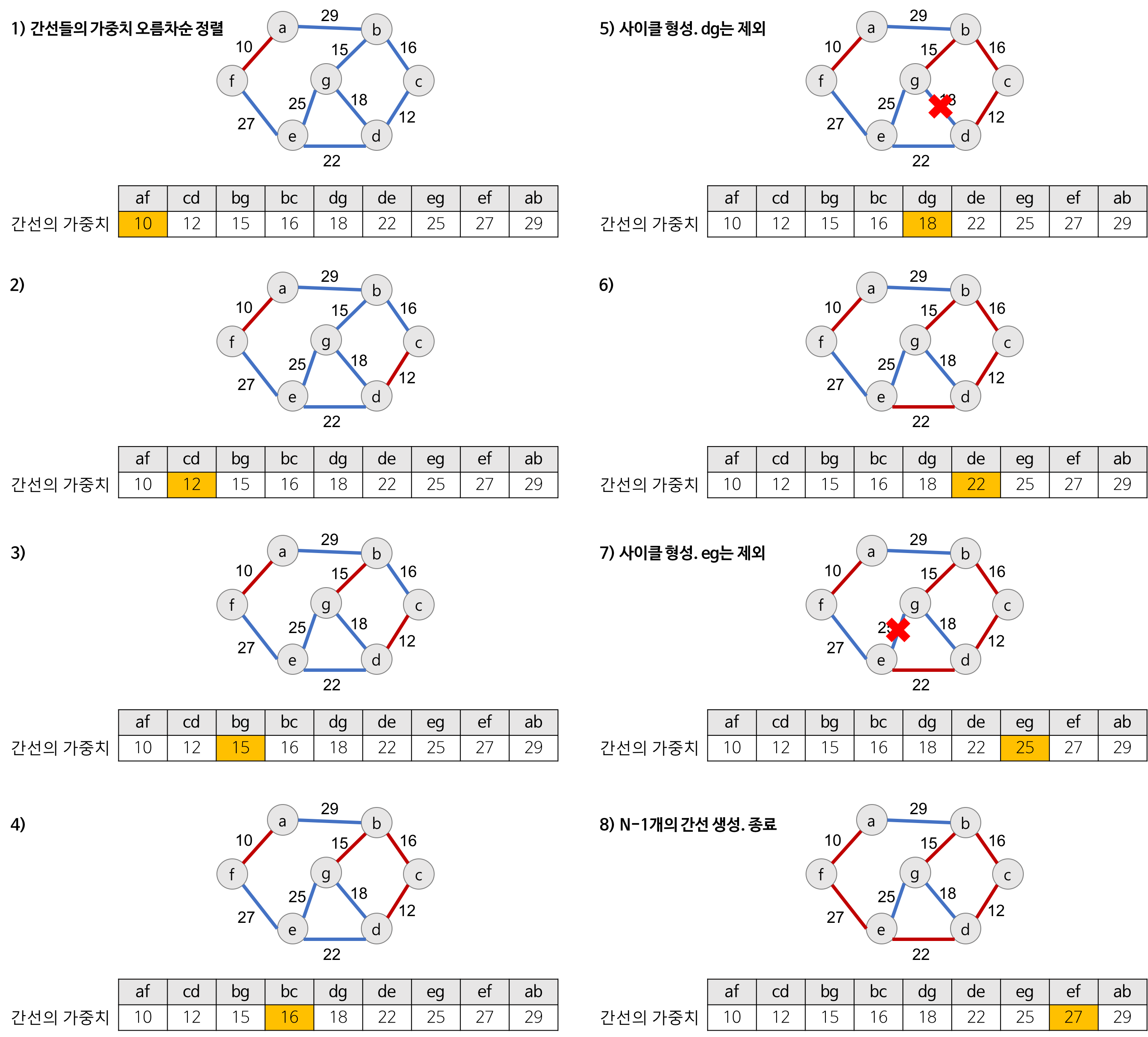
위 과정에서 중요한 것은 간선을 추가하면서 사이클을 생성하는지 체크 하는 것이다.
5, 7번째 과정을 보면 각각 dg 간선과 eg 간선은 사이클을 형성하게 되므로 트리에 추가하지 않는다.
사이클 생성 여부 검사는 추가하고자 하는 간선의 양끝 정점이 같은 집합에 속해 있는지 검사하는 union-find 알고리즘을 사용하게 된다.
코드로 보는 크루스칼 알고리즘
Python
# 특정 원소가 속한 집합을 찾기
def find_parent(parent, x):
# 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
# 두 원소가 속한 집합을 합치기
def union_parent(parent, a, b):
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
# 노드의 개수와 간선(union 연산)의 개수 입력받기
v, e = map(int, input().split())
parent = [0] * (v+1) # 부모 테이블 초기화
# 모든 간선을 담을 리스트와 최종 비용을 담을 변수
edges = []
result = 0
# 부모 테이블상에서, 부모를 자기 자신으로 초기화
for i in range(1, v+1):
parent[i] = i
# 모든 간선에 대한 정보를 입력받기
for _ in range(e):
a, b, cost = map(int, input().split())
# 비용순으로 정렬하기 위해서 튜플의 첫 번째 원소를 비용으로 설정
edges.append((cost, a, b))
# 간선을 비용순으로 정렬
edges.sort()
# 간선을 하나씩 확인하며
for edge in edges:
cost, a, b = edge
# 사이클이 발생하지 않는 경우에만 집합에 포함 (parent가 다른 경우)
if find_parent(parent, a) != find_parent(parent, b):
union_parent(parent, a, b)
result += cost
print(result)
Java
import java.io.*;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.StringTokenizer;
// 간선 class
class Edge {
int s, e, cost;
Edge(int s, int e, int cost) {
this.s = s;
this.e = e;
this.cost = cost;
}
}
public class Main {
public static int[] parent;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
// 노드의 개수와 간선(union 연산)의 개수 입력받기
int V = Integer.parseInt(st.nextToken());
int E = Integer.parseInt(st.nextToken());
ArrayList<Edge> edges = new ArrayList<>();
int answer = 0;
// 모든 간선에 대한 정보를 입력받기
for (int i = 0; i < E; i++) {
st = new StringTokenizer(br.readLine());
int start = Integer.parseInt(st.nextToken());
int end = Integer.parseInt(st.nextToken());
int cost = Integer.parseInt(st.nextToken());
edges.add(new Edge(start, end, cost));
}
// 간선을 비용순으로 정렬
edges.sort(new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return Integer.compare(o1.cost, o2.cost);
}
});
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
parent = new int[V + 1];
for (int i = 1; i <= V; i++) {
parent[i] = i;
}
for (int i = 0; i < E; i++) {
Edge edge = edges.get(i);
// 사이클이 발생하지 않는 경우에만 집합에 포함 (parent가 다른 경우)
if (!isSameParent(edge.s, edge.e)) {
union(edge.s, edge.e);
answer += edge.cost;
}
}
bw.write(answer + "\n");
br.close();
bw.flush();
bw.close();
}
// 특정 원소가 속한 집합을 찾기
public static int find(int x) {
if (parent[x] == x) {
return x;
} else {
return parent[x] = find(parent[x]);
}
}
// 두 원소가 같은 부모를 가지는지 확인
public static boolean isSameParent(int x, int y) {
x = find(x);
y = find(y);
if (x == y) {
return true;
} else {
return false;
}
}
// 두 원소가 속한 집합을 합치기
public static void union(int x, int y) {
x = find(x);
y = find(y);
if (x != y) {
parent[y] = x;
}
}
}
크루스칼 알고리즘 시간복잡도
- union-find로 사이클 검사를 하면 Kruskal 알고리즘의 시간 복잡도는 간선들을 정렬하는 시간에 좌우된다
- 간선 e개를 효율적인 알고리즘으로 정렬한다면 가 된다.
Prim 알고리즘과의 비교
MST를 만드는 다른 알고리즘인 Prim 알고리즘의 경우 인접행렬로 구현했을 때 의 시간복잡도를 가진다.
- 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph)의 경우 Kruskal 알고리즘이 적합하다
- 그래프에 간선이 많이 존재하는 밀집 그래프(Dense Graph)의 경우 Prim 알고리즘이 적합하다
대표적인 크루스칼 알고리즘 문제
면접에 나올 수 있는 질문
Q. 크루스칼 알고리즘이란?
A. 크루스칼 알고리즘은 가장 적은 비용으로 모든 노드를 연결하기 위해 사용하는 알고리즘으로, MST를 만들기 위한 대표적인 알고리즘이다.
Q. 크루스칼 알고리즘의 시간복잡도는?
A. 크루스칼 알고리즘은 간선의 개수가 e개일때 의 시간복잡도를 가진다.
Q. 크루스칼 알고리즘과 프림 알고리즘 중 어느 것을 쓰는게 좋을까?
A. 크루스칼 알고리즘의 경우 간선의 개수가 e일때 의 시간복잡도를, 프림 알고리즘은 인접 행렬로 구현 했을 때 정점의 개수가 v일때 의 시간복잡도를 가지게 된다.
따라서 간선이 많은 그래프의 경우 프림 알고리즘을, 간선이 적은 경우 크루스칼 알고리즘을 사용하는 것이 좋다.
참고
기여자

Jongminfire
📦